Figure fig:wnpropagate
Free hyper parameters: the seed-sets, the
WordNet relations called in SamePolarity and OtherPolarity, the number
of iterations, the decision to remove overlap.

Many sentiment applications rely on lexicons to supply features to a model. This section reviews some publicly available resources and their relationships, and it seeks to identify some best practices for using sentiment lexicons effectively.
Bing Liu maintains and freely distributes a sentiment lexicon consisting of lists of strings.
The MPQA (Multi-Perspective Question Answering) Subjectivity Lexicon is maintained by Theresa Wilson, Janyce Wiebe, and Paul Hoffmann (Wiebe, Wilson, and Cardie 2005). It is distributed under a GNU Public License. Table tab:mpqa shows what its structure is like.
| Strength | Length | Word | Part-of-speech | Stemmed | Polarity | |
|---|---|---|---|---|---|---|
| 1. | type=weaksubj | len=1 | word1=abandoned | pos1=adj | stemmed1=n | priorpolarity=negative |
| 2. | type=weaksubj | len=1 | word1=abandonment | pos1=noun | stemmed1=n | priorpolarity=negative |
| 3. | type=weaksubj | len=1 | word1=abandon | pos1=verb | stemmed1=y | priorpolarity=negative |
| 4. | type=strongsubj | len=1 | word1=abase | pos1=verb | stemmed1=y | priorpolarity=negative |
| 5. | type=strongsubj | len=1 | word1=abasement | pos1=anypos | stemmed1=y | priorpolarity=negative |
| 6. | type=strongsubj | len=1 | word1=abash | pos1=verb | stemmed1=y | priorpolarity=negative |
| 7. | type=weaksubj | len=1 | word1=abate | pos1=verb | stemmed1=y | priorpolarity=negative |
| 8. | type=weaksubj | len=1 | word1=abdicate | pos1=verb | stemmed1=y | priorpolarity=negative |
| 9. | type=strongsubj | len=1 | word1=aberration | pos1=adj | stemmed1=n | priorpolarity=negative |
| 10. | type=strongsubj | len=1 | word1=aberration | pos1=noun | stemmed1=n | priorpolarity=negative |
| ... | ||||||
| 8221. | type=strongsubj | len=1 | word1=zest | pos1=noun | stemmed1=n | priorpolarity=positive |
SentiWordNet (note: this site was hacked recently; take care when visiting it) (Baccianella, Esuli, and Sebastiani 2010) attaches positive and negative real-valued sentiment scores to WordNet synsets (Fellbaum1998). It is freely distributed for noncommercial use, and licensed are available for commercial applications. (See the website for details.) Table tab:sentiwordnet summarizes its structure. (For extensive discussion of WordNet synsets and related objects, see this introduction).
| POS | ID | PosScore | NegScore | SynsetTerms | Gloss |
|---|---|---|---|---|---|
| a | 00001740 | 0.125 | 0 | able#1 | (usually followed by `to') having the necessary means or [...] |
| a | 00002098 | 0 | 0.75 | unable#1 | (usually followed by `to') not having the necessary means or [...] |
| a | 00002312 | 0 | 0 | dorsal#2 abaxial#1 | facing away from the axis of an organ or organism; [...] |
| a | 00002527 | 0 | 0 | ventral#2 adaxial#1 | nearest to or facing toward the axis of an organ or organism; [...] |
| a | 00002730 | 0 | 0 | acroscopic#1 | facing or on the side toward the apex |
| a | 00002843 | 0 | 0 | basiscopic#1 | facing or on the side toward the base |
| a | 00002956 | 0 | 0 | abducting#1 abducent#1 | especially of muscles; [...] |
| a | 00003131 | 0 | 0 | adductive#1 adducting#1 adducent#1 | especially of muscles; [...] |
| a | 00003356 | 0 | 0 | nascent#1 | being born or beginning; [...] |
| a | 00003553 | 0 | 0 | emerging#2 emergent#2 | coming into existence; [...] |
The Harvard General Inquirer is a lexicon attaching syntactic, semantic, and pragmatic information to part-of-speech tagged words (Stone, Dunphry, Smith, and Ogilvie 1966). The spreadsheet format is the easiest one to work with for most computational applications. Table tab:inquirer provides a glimpse of the richness and complexity of this resource.
| Entry | Positiv | Negativ | Hostile | ...184 classes ... | Othtags | Defined | |
|---|---|---|---|---|---|---|---|
| 1 | A | DET ART | ... | ||||
| 2 | ABANDON | Negativ | SUPV | ||||
| 3 | ABANDONMENT | Negativ | Noun | ||||
| 4 | ABATE | Negativ | SUPV | ||||
| 5 | ABATEMENT | Noun | |||||
| ... | |||||||
| 35 | ABSENT#1 | Negativ | Modif | ||||
| 36 | ABSENT#2 | SUPV | |||||
| ... | |||||||
| 11788 | ZONE | Noun | |||||
Linguistic Inquiry and Word Counts (LIWC) is a propriety database consisting of a lot of categorized regular expressions. It costs about $90. Its classifications are highly correlated with those of the Harvard General Inquirer. Table tab:liwc gives some of its sentiment-relevant categories with example regular expressions.
| Category | Examples |
|---|---|
| Negate | aint, ain't, arent, aren't, cannot, cant, can't, couldnt, ... |
| Swear | arse, arsehole*, arses, ass, asses, asshole*, bastard*, ... |
| Social | acquainta*, admit, admits, admitted, admitting, adult, adults, advice, advis* |
| Affect | abandon*, abuse*, abusi*, accept, accepta*, accepted, accepting, accepts, ache* |
| Posemo | accept, accepta*, accepted, accepting, accepts, active*, admir*, ador*, advantag* |
| Negemo | abandon*, abuse*, abusi*, ache*, aching, advers*, afraid, aggravat*, aggress*, |
| Anx | afraid, alarm*, anguish*, anxi*, apprehens*, asham*, aversi*, avoid*, awkward* |
| Anger | jealous*, jerk, jerked, jerks, kill*, liar*, lied, lies, lous*, ludicrous*, lying, mad |
All of the above lexicons provide basic polarity classifications. Their underlying vocabularies are different, so it is difficult to compare them comprehensively, but we can see how often they explicitly disagree with each other in that they supply opposite polarity values for a given word. Table tab:lexicon_disagreement reports on the results of such comparisons.
(Where a lexicon had part-of-speech tags, I removed them and selected the most sentiment-rich sense available for the resulting string. For SentiWordNet, I counted a word as positive if its positive score was larger than its negative score; negative if its negative score was larger than its positive score; else neutral, which means that words with equal non-0 positive and negative scores are neutral.)
| MPQA | Opinion Lexicon | Inquirer | SentiWordNet | LIWC | |
|---|---|---|---|---|---|
| MPQA | – | 33/5402 (0.6%) | 49/2867 (2%) | 1127/4214 (27%) | 12/363 (3%) |
| Opinion Lexicon | – | 32/2411 (1%) | 1004/3994 (25%) | 9/403 (2%) | |
| Inquirer | – | 520/2306 (23%) | 1/204 (0.5%) | ||
| SentiWordNet | – | 174/694 (25%) | |||
| LIWC | – |
I can imagine two equally reasonable reaction to the disagreements. The first would be to resolve them in favor of some particular sense. The second would be to combine the values derived from theses resources, thereby allowing the conflicts to persist, as a way of capturing the fact that the disagreements arise from genuine sense ambiguities.
The above lexicons are useful for a wide range of tasks, but they are fixed resources. This section is devoted to developing new resources. This can have three benefits, which we will see in various combinations:
The guiding idea behind simple WordNet propagation is the properties of some hand-selected seed-sets will be preserved as we travel strategically through WordNet (Hu and Liu 2004 Andreevskaia and Bergler 2006 Esuli and Sebastiani 2006 Kim and Hovy 2006 Godbole, Srinivasaiah, and Skiena 2007 Rao and Ravichandran 2009).
The algorithm begins with n small, hand-crafted seed-sets and then follows WordNet relations from them, thereby expanding their size. The expanded sets of iteration i are used as seed-sets for iteration i+1, generally after pruning any pairwise overlap between them.
The algorithm is spelled out in full in figure fig:wnpropagate.
The algorithm has a number of free parameters: the seed-sets, the WordNet relations called in SamePolarity and OtherPolarity, the number of iterations, the decision to remove overlap. The demo allows you to try out different combinations of values:
Table tab:wnpropagate_exs provides some additional seed-sets, drawing from other distinctions found in the Harvard Inquirer. These can be pasted into the demo if one wants a sense for how well new lexical classes propagate.
| Category | Seed set |
|---|---|
| Pleasur | amuse, calm, ecstasy, enjoy, joy |
| Pain | agony, disconcerted, fearful, regret, remorse |
| Strong | illustrious, rich, control, perseverance |
| Weak | lowly, poor, sorry, sluggish, weak |
| MALE | boy, brother, gentleman, male, guy |
| Female | girl, sister, bride, female, lady |
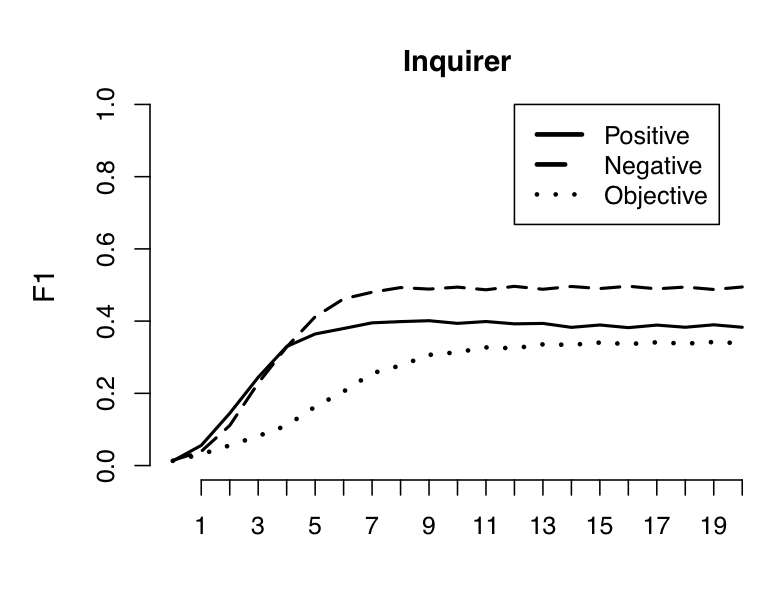
To assess the algorithm for polarity sense-preservation, I began with the seed-sets in table tab:seeds and then allowed the propagation algorithm to run for 20 iterations, checking each for its effectiveness at reproducing the Positiv/Negativ/Neither distinctions in the subset of Harvard General Inquirer that is also in WordNet.
| Positive | excellent, good, nice, positive, fortunate, correct, superior |
| Negative | nasty, bad, poor, negative, unfortunate, wrong, inferior |
| Objective | administrative, financial, geographic, constitute, analogy, ponder, material, public, department, measurement, visual |
Figure fig:wnpropagate-assess summarizes the results of this experiment, which are decidedly mixed.
Blair-Goldensohn, Hannan, McDonald, Ryan, Reis, and Reynar (2008) developed an algorithm that propagates not only the senses of the original seed set but also attaches scores to words, reflecting their intensity, which here is given by the strength of their graphical connections to the seed words. The algorithm is stated in figure fig:wnscores_algorithm.

Figure fig:wnscores_example works through an example.

I ran the algorithm using the full Harvard General Inquirer Positiv/Negative/Neither classes as seeds-sets. The output in archived CSV format:
You can view the results at the lexicon demo.
In my informal assessment, the positive and negative scores it assigns tend to be accurate. The disappointment is that so many of the scores are 0, as see in figure fig:wnscores_scoredist. I think this could be addressed by following more relations that just the basic synset one, as we do for the simple WordNet propagation algorithm, but I've not tried it yet.

In this section, I make use of the CSV-formatted data here:
This is a tightly controlled, POS-tagged dataset. Even more carefully curated ones are here, drawing from a wider range of corpora:
And for more naturalistic, non-POS-tagged data in this format from a variety of sources:
The methods are discussed and motivated in Constant, Davis, Potts, and Schwarz 2008 and Potts and Schwarz 2010, and this page provides a more extended discussion with associated R code.
The file http://compprag.christopherpotts.net/code-data/imdb-words.csv.zip consists of data gathered from the user-supplied reviews at the IMDB. I suggest that you take a moment right now to browse around the site a bit to get a feel for the nature of the reviews — their style, tone, and so forth.
The focus of this section is the relationship between the review authors' language and the star ratings they choose to assign, from the range 1-10 stars (with the exception of This is Spinal Tap, which goes to 11). Intuitively, the idea is that the author's chosen star rating affects, and is affected by, the text she produces. The star rating is a particular kind of high-level summary of the evaluative aspects of the review text, and thus we can use that high-level summary to get a grip on what's happening linguistically.
The data I'll be working with are all in the format described in table tab:data. Each row represents a star-rating category. Thus, for example, in these data, (bad, a) is used 122,232 in 1-star reviews, and the total token count for 1-star reviews is 25,395,214.
| Word | Tag | Category | Count | Total |
|---|---|---|---|---|
| bad | a | 1 | 122232 | 25395214 |
| bad | a | 2 | 40491 | 11755132 |
| bad | a | 3 | 37787 | 13995838 |
| bad | a | 4 | 33070 | 14963866 |
| bad | a | 5 | 39205 | 20390515 |
| bad | a | 6 | 43101 | 27420036 |
| bad | a | 7 | 46696 | 40192077 |
| bad | a | 8 | 42228 | 48723444 |
| bad | a | 9 | 29588 | 40277743 |
| bad | a | 10 | 51778 | 73948447 |
The next few sections describe methods for deriving sentiment lexicons from such data. The methods should generalize to other kinds of ordered sentiment metadata (e.g., helpfulness ratings, confidence ratings).
A common feature of online user-supplied reviews is that the positive reviews vastly out-number the negative ones; see figure fig:totals.
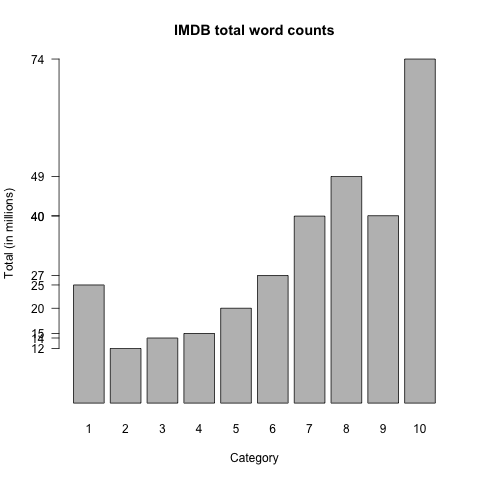
As we saw above, the raw Count values are likely to be misleading due to the very large size imbalances among the categories. For example, there are more tokens of (bad, a) in 10-star reviews than in 2-star ones, which seems highly counter-intuitive. Plotting the values reveals that the Count distribution is very heavily influenced by the overall distribution of words (figure fig:counts).

The source of this odd picture is clear: the 10-star category is 7 times bigger than the 1-star category, so the absolute counts do not necessarily reflect the rate of usage.
To get a better read on the usage patterns, we use relative frequencies:
Table tab:relfreq extends table tab:data with these RelFreq values.
| Word | Tag | Category | Count | Total | RelFreq |
|---|---|---|---|---|---|
| bad | a | 1 | 122232 | 25395214 | 0.0048 |
| bad | a | 2 | 40491 | 11755132 | 0.0034 |
| bad | a | 3 | 37787 | 13995838 | 0.0027 |
| bad | a | 4 | 33070 | 14963866 | 0.0022 |
| bad | a | 5 | 39205 | 20390515 | 0.0019 |
| bad | a | 6 | 43101 | 27420036 | 0.0016 |
| bad | a | 7 | 46696 | 40192077 | 0.0012 |
| bad | a | 8 | 42228 | 48723444 | 0.0009 |
| bad | a | 9 | 29588 | 40277743 | 0.0007 |
| bad | a | 10 | 51778 | 73948447 | 0.0007 |
Relative frequency values are hard to get a grip on intuitively because they are so small. Plotting helps bring out the relationships between the values, as in figure fig:relfreq.
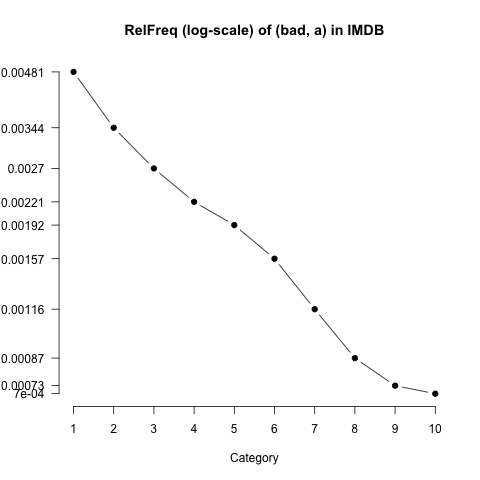
One drawback to RelFreq values is that they are highly sensitive to overall frequency. For example, (bad, a) is significantly more frequent than (horrible, a), which means that the RelFreq values for the two words are hard to directly compare. Figure fig:relfreq_cmp nonetheless attempts a comparison.

It is possible to discern that (bad, a) is less extreme in its negativity than (horrible, a). However, the effect looks subtle. The next measure we look at abstracts away from overall frequency, which facilitates this kind of direct comparison.
A drawback to RelFreq values, at least for present purposes, is that they are extremely sensitive to the overall frequency of the word in question. There is a comparable value that is insensitive to this quantity:
Pr values are just rescaled RelFreq values: we divide by a constant to get from RelFreq to Pr. As a result, the distributions have exactly the same shape, as we see in figure fig:pr.
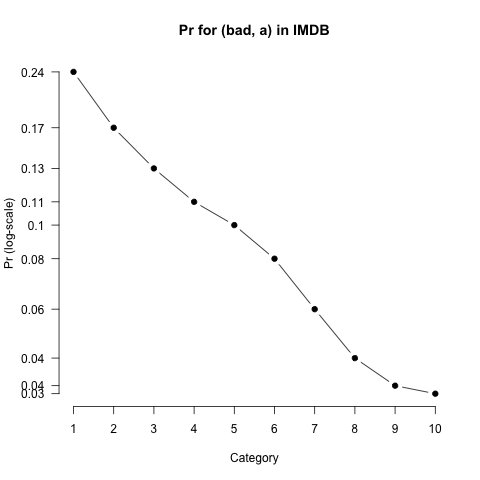
A technical note: The move from RelFreq to Pr involves an application of Bayes Rule.
Pr values greatly facilitate comparisons between words (figure fig:pr_cmp).

I think these plots clearly convey that (bad, a) is less intensely negative than (horrible, a). For example, whereas (bad, a) is at least used throughout the scale, even at the top, (horrible, a) is effectively never used at the top of the scale.
(For methods that rigorously compare word distributions of this sort, see this write-up, this talk, and Davis 2011.)
We are now in a position to assign polarity scores to words. A first method for doing this uses expected ratings:
Subtracting 5.5 from the Category values centers them at 0, so that we can treat scores below 0 as negative and scores above 0 as positive.
Expected ratings calculations are used by de Marneffe et al. 2010 to summarize Pr-based distributions. The expected rating calculation is just a weighted average of Pr values.
To get a feel for these values, it helps to work through some examples:

To get sentiment classification and intensity, we treat words with ER values below 0 as negative, those with ER valus above 0 as positive, and then use the absolute values as measures of intensity:
Expected ratings are easy to calculate and quite intuitive, but it is hard to know how confident we can be in them, because they are insensitive to the amount and kind of data that went into them. Suppose the ER for words v and w are both 10, but we have 500 tokens of v and just 10 tokens of w. This suggests that we can have a high degree of confidence in our ER for v, but not for w. However, ER values don't encode this uncertainty, nor is there an obvious way to capture it.
Logistic regression provides a useful way to do the work of ERs but with the added benefits of having a model and associated test statistics and measures of confidence. For our purposes, we can stick to a simple model that uses Category values to predict word usage. The intuition here is just the one that we have been working with so far: the star-ratings are correlated with the usage of some words. For a word like (bad, a), the correlation is negative: usage drops as the ratings get higher. For a word like (amazing, a), the correlation is positive.
With our logistic regression models, we will essentially fit lines through our RelFreq data points, just as one would with a linear regression involving one predictor. However, the logistic regression model fits these values in log-odds space and uses the inverse logit function (plogis in R) to ensure that all the predicted values lie in [0,1], i.e., that they are all true probability values. Unfortunately, there is not enough time to go into much more detail about the nature of this kind of modeling. I refer to Gelman and Hill 2008, §5-6 for an accessible, empirically-driven overview. Instead, let's simply fit a model and try to build up intuitions about what it does and says.
The simple linear regression model for bad is given in table tab:bad_fit. The model simply uses the rating values to predict the usage (log-odds) of the word in each category.
| Coefficient Estimate | Standard Error | t value | p | |
|---|---|---|---|---|
| Intercept | -5.16 | 0.046 | -112.49 | < 0.00001 |
| Category | -0.22 | 0.008 | -27.96 | < 0.00001 |
This model is plotted on figure fig:bad_fit.
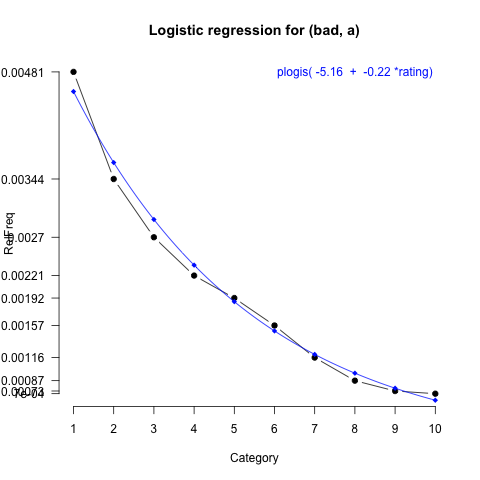
Here, we can use the coefficient for Category as our sentiment score. Where the value is negative (negative slope), the word is negative. Where it is positive, the word is positive. Informally, we can also use the size of the coefficient as a measure of its intensity.
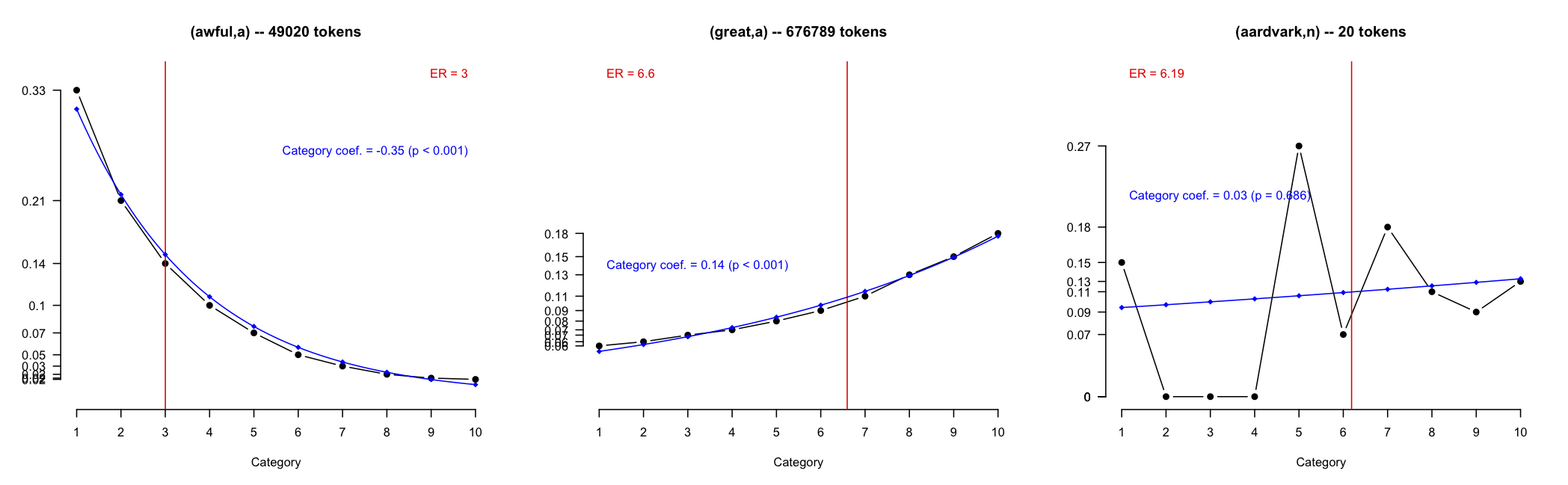
The great strength of this approach is that we can use the p-values to determine whether a score is trustworthy. Figure fig:cmp helps to convey why this is an important new power. (Here and in later plots, I've rescaled the values into Pr space to facilitate comparisons.)
This leads to the following method for inducing a sentiment lexicon from these data:
Depending on where the significance value is set, this can learn conservative lexicons of a few thousand words or very liberal lexicons of tens of thousands.
This method of comparing coefficient values is likely to irk statisticians, but it works well in practice. For a more exact and careful method, as well as a proposal for how to compare words with non-linear relationships to the ratings, see this talk I gave recently on creating lexical scales.
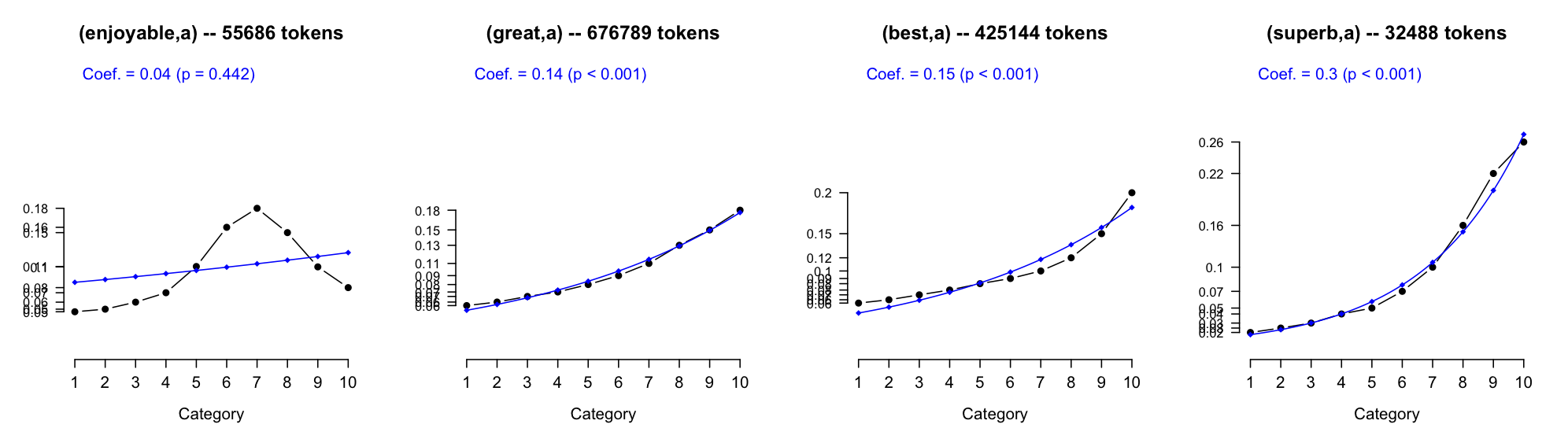
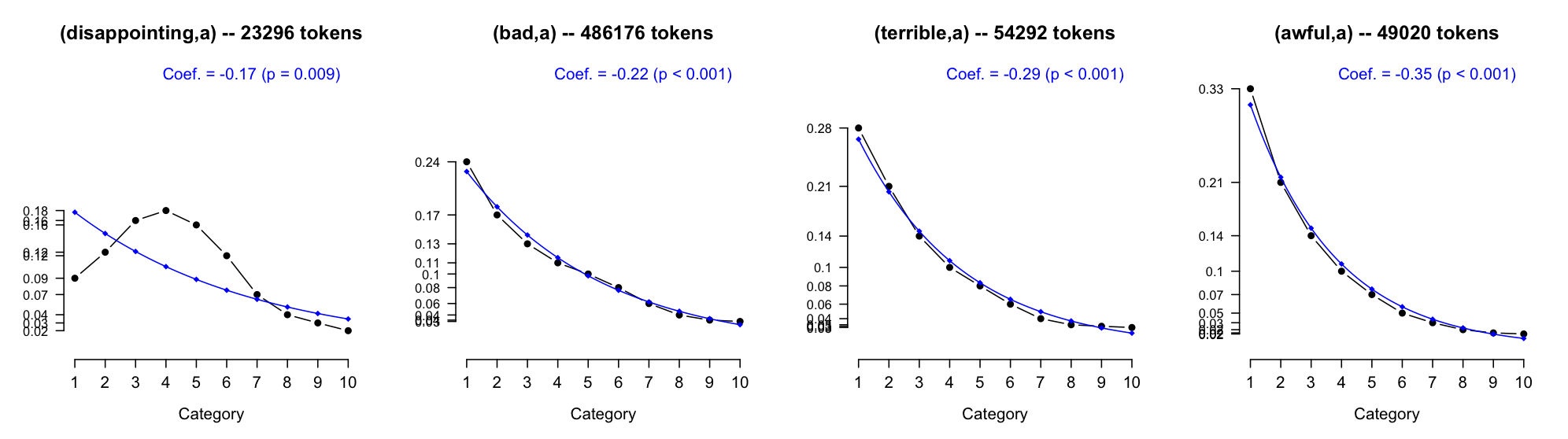
Figure fig:scalars shows off this new method of lexicon induction.
The Experience Project is a social networking website that allows users to share stories about their own personal experiences. At the confessions portion of the site, users write typically very emotional stories about themselves, and readers can then chose from among five reaction categories to the story, but clicking on one of the five icons in figure fig:ep_cats. The categories provide rich new dimensions of sentiment, ones that are generally orthogonal to the positive/negative one that most people study but that nonetheless models important aspects of sentiment expression and social interaction (Potts 2010b, Socher, Pennington, Huang, Ng and Manning 2011).

This section presents a simple method for using these data to develop sentiment lexicons.
As with the IMDB data above, I've put the word-level information into an easy-to-use CSV format, as in table tab:ep_data. Thus, as long as you require only word-level statistics, you needn't scrape the site again.
| Word | Category | Count | Total |
|---|---|---|---|
| bad | hugs | 11612 | 18038374 |
| bad | rock | 5711 | 14066087 |
| bad | teehee | 3987 | 8167037 |
| bad | understand | 12577 | 20466744 |
| bad | wow | 5993 | 12550603 |
The basic scoring method contrasts observed click rates with expected click rates on the assumption that all word–click combinations are equally likely:
Table tab:oe extends table tab:ep_data with Expected and O/E values.
| Word | Category | Count | Total | Expected | O/E |
|---|---|---|---|---|---|
| bad | hugs | 11612 | 18038374 | 9816.527 | 1.1829030 |
| bad | rock | 5711 | 14066087 | 7652.981 | 0.7462452 |
| bad | teehee | 3987 | 8167037 | 4443.831 | 0.8971989 |
| bad | understand | 12577 | 20466744 | 11137.727 | 1.1292250 |
| bad | wow | 5993 | 12550603 | 6828.934 | 0.8775893 |
Some representative cases:



These scores give rise to a multidimensional lexical entry via the following definition:
The lexicon demos include both IMDB and EP scores as well: