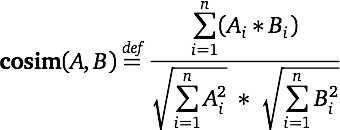
This section introduces some basic techniques from the study of vector-space models. In the present setting, the guiding idea behind such models is that important aspects of a word's meanings are latent in its distribution, that is, in its patterns of co-occurrence with other words.
I focus on word–word matrices, rather than the more familiar and widely used word–document matrices of information retrieval and much of computational semantics. The reason for this is simply that, on the data I was experimenting with, this design seemed to be delivering better results with fewer resources.
Turney and Pantel 2010 is a highly readable introduction to vector-space models, covering a wide variety of different design choices and applications. I highly recommend it for anyone aiming to implement and deploy models like this.
A word–word for a vocabulary V of size n is an n × n matrix in which both the rows and columns represent words in V. The value in cell (i, j) is the number of times that word i and word j appear together in the same context.
Table tab:wordword depicts a fragment of a word–word matrix derived from 12,000 OpenTable reviews, using the sentiment + negation tokenization scheme motivated earlier. Here, the counts for (i, j) are the number of times that word i and word j appear together in the same review. With this matrix design, the rows and columns are the same, though they might be very different with other matrix designs.
| a | a_neg | able | able_neg | about | about_neg | above | |
|---|---|---|---|---|---|---|---|
| a | 32620 | 4101 | 340 | 110 | 2066 | 551 | 122 |
| a_neg | 4101 | 3286 | 31 | 41 | 312 | 142 | 21 |
| able | 340 | 31 | 163 | 2 | 16 | 4 | 0 |
| able_neg | 110 | 41 | 2 | 63 | 6 | 7 | 2 |
| about | 2066 | 312 | 16 | 6 | 1177 | 37 | 9 |
| about_neg | 551 | 142 | 4 | 7 | 37 | 365 | 1 |
| above | 122 | 21 | 0 | 2 | 9 | 1 | 88 |
We now want to measure how similar the row vectors are to one another. If we compare the raw count vectors (say, by using Euclidean distance), then the dominating factor will be overall corpus frequency, which is unlikely to be sentiment relevant. Cosine similarity addresses this by comparing length normalized vectors:
In table tab:cosine, I picked two sentiment rich target words, excellent and terrible, and compared them for cosine similarity against the whole vocabulary. The figure provides the 20 closest words by this similarity measure. Though the lists contain more function words than we might like, there are also rich sentiment words, some of them specific to the domain of restaurants, which suggest that we might use this method to increase our lexicon size in a context-dependent manner.
| excellent | terrible |
|---|---|
| excellent | terrible |
| service | . |
| food | was |
| and | bad |
| attentive | service |
| . | food |
| friendly | poor |
| atmosphere | over |
| delicious | there |
| prepared | completely |
| definitely | disappointed |
| ambiance | just |
| comfortable | about |
| with | eating |
| the | only |
| choice | horrible |
| well | almost |
| recommended | seemed |
| experience | even |
| outstanding | probably |
Singular value decomposition (SVD; see also the Latent Semantic Analysis of Deerwester, Dumais, Furnas, Landauer, and Harshman 1990) is a dimensionality reduction technique that has been shown to uncover a lot of underlying semantic structure. Table tab:svd shows the result of length normalizing the word–word matrix and then applying SVD to the result.
| a | a_neg | able | able_neg | about | about_neg | above | |
|---|---|---|---|---|---|---|---|
| a | -0.00012 | -0.00028 | -0.00109 | -0.00139 | -0.00279 | 0.00115 | 0.00078 |
| a_neg | -0.00186 | 0.00077 | 0.00846 | 0.00823 | 0.00457 | 0.00099 | 0.00147 |
| able | 0.01790 | -0.01113 | 0.01530 | -0.00409 | -0.01084 | -0.01161 | -0.01337 |
| able_neg | 0.00560 | 0.00871 | 0.00003 | 0.00596 | 0.01057 | -0.01821 | -0.00289 |
| about | 0.02486 | 0.01737 | -0.02056 | -0.01453 | 0.01422 | 0.01922 | 0.05323 |
| about_neg | 0.00514 | 0.00212 | 0.00252 | 0.00847 | 0.01624 | 0.01034 | 0.00013 |
| above | 0.00663 | -0.02498 | 0.01634 | 0.00680 | -0.00898 | 0.00609 | -0.00667 |
If we compare the new vectors, the results are somewhat different. To my eye, they look messier from a sentiment perspective. Going forward, I'll stick with the simpler method of just using cosine similarity on the raw count vectors.
| excellent | terrible |
|---|---|
| excellent | terrible |
| said | fish |
| about | friend |
| some | had_NEG |
| potatoes | left_NEG |
| ambiance | so-so |
| ... | or_NEG |
| bar | dessert |
| i'm | especially |
| what | curry |
| you_NEG | saturday_NEG |
| little | again_NEG |
| got | pre |
| his | expectations |
| be_NEG | of |
| enough_NEG | inattentive |
| are | attentive |
| later_NEG | when |
| snapper | patrons |
| tables | you've |
There are many, many design choices available for vector-space models. We can vary not only the matrix itself but also the kinds of dimensionality reduction we perform (if any) and the similarity measures we employ. I refer to Turney and Pantel 2010 for a thorough overview. Here, I confine myself to mentioning a few other matrix designs that might be valuable for sentiment analysis:
Turney and Littman (2003) generalize the informal procedure used above, to achieve a general lexicon learning method. Their approach:
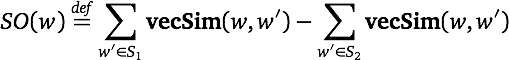
Turney and Littman explore a number of different weighting schemes and similarity measures, paying special attention to how well they do on various corpus sizes. They conjecture that their approach can be generalized to a wide variety of sentiment contrasts.
I tried out a simple version of their approach on the OpenTable subset used above. The matrix was an unweighted word–word matrix, and the vector similarity measure was cosine similarity. The seed sets I used (table tab:so_seeds) are designed to aim for positive and negative words used to describe eating and good restaurant experiences. The top 20 positive and negative words are given in table tab:so. The results look extremely promising to me.
| positive words | good, excellent, delicious, tasty, pleasant |
| negative words | bad, spoiled, awful, rude, gross |
| Positive | Negative |
|---|---|
| excellent | rude |
| delicious | awful |
| good | bad |
| tasty | worst |
| pleasant | acted |
| very | apologies_NEG |
| service | attitude |
| great | unprofessional |
| attentive | desserts_NEG |
| friendly | complained |
| restaurant | NEVER |
| all | recommending_NEG |
| my | customer_NEG |
| menu | terrible |
| recommend | HORRIBLE |
| experience | rude_NEG |
| nice | questions_NEG |
| atmosphere | ridiculous |
| wine | taking_NEG |
| well | watery |
The method of Velikovich, Blair-Goldensohn, Hannan, and McDonald (2010) is closely related to that of Turney and Littman 2003, except that it extends the idea with a sophisticated and somewhat mind-bending propagation component aimed at learning truly massive sentiment lexicons.
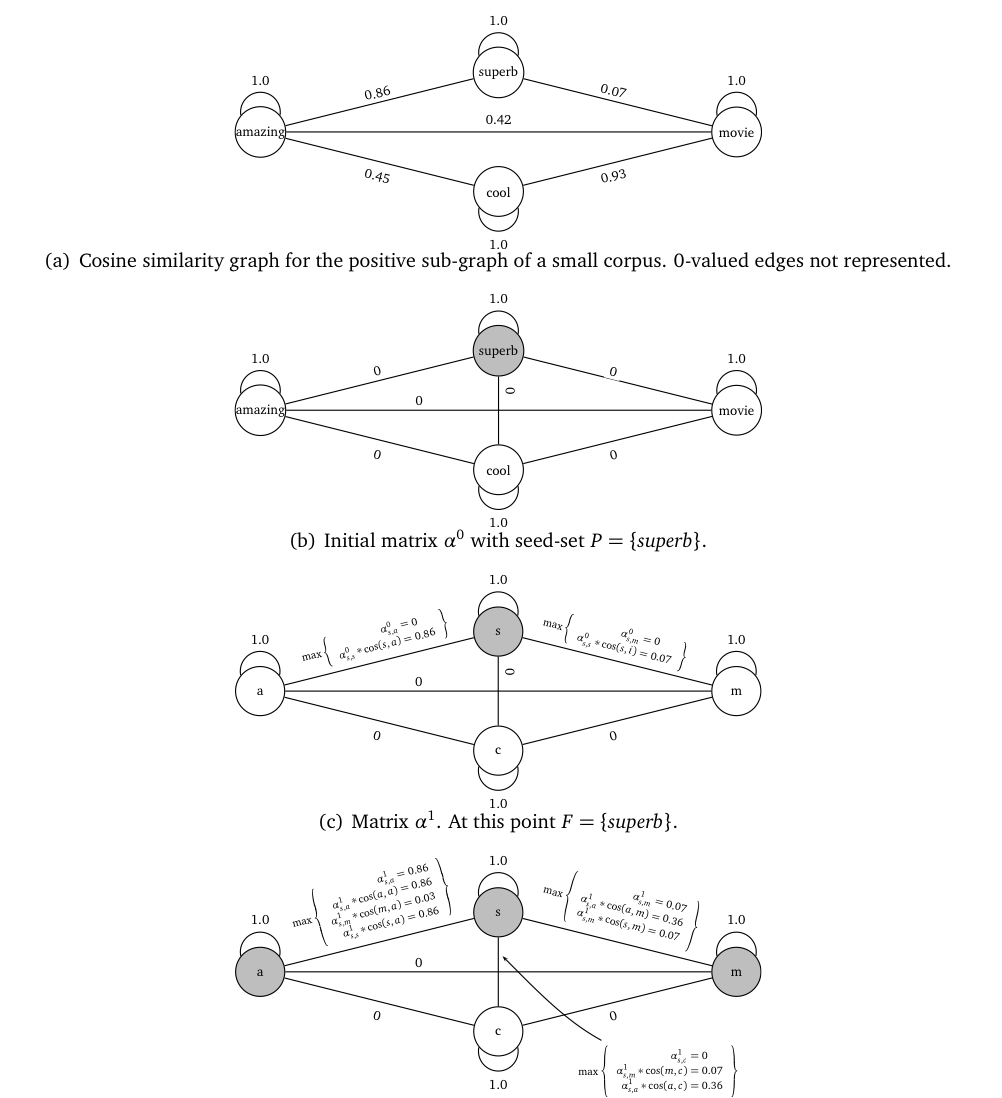
The algorithm is defined in figure fig:webprop_algorithm.

I use the simple example in table tab:webprop_ex illustrate how the algorithm works.
| Corpus |
|---|
| superb amazing |
| superb movie |
| superb movie |
| superb movie |
| superb movie |
| superb movie |
| amazing movie |
| amazing movie |
| cool superb |
| amazing | cool | movie | superb | |
|---|---|---|---|---|
| amazing | 0 | 0 | 2 | 1 |
| cool | 0 | 0 | 0 | 1 |
| movie | 2 | 0 | 0 | 5 |
| superb | 1 | 1 | 5 | 0 |
| amazing | cool | movie | superb | |
|---|---|---|---|---|
| amazing | 1.0 | 0.45 | 0.42 | 0.86 |
| cool | 0.45 | 1.0 | 0.93 | 0.0 |
| movie | 0.42 | 0.93 | 1.0 | 0.07 |
| superb | 0.86 | 0.0 | 0.07 | 1.0 |
Figure fig:webprop_example continues the above example by showing how propagation works.
Velikovich et al. build a truly massive graph:
For this study, we used an English graph where the node set V was based on all n-grams up to length 10 extracted from 4 billion web pages. This list was filtered to 20 million candidate phrases using a number of heuristics including frequency and mutual information of word boundaries. A context vector for each candidate phrase was then constructed based on a window of size six aggregated over all mentions of the phrase in the 4 billion documents. The edge set $E$ was constructed by first, for each potential edge (vi,vj), computing the cosine similarity value between context vectors. All edges (vi,vj) were then discarded if they were not one of the 25 highest weighted edges adjacent to either node vi or vj.
Some highlights of their lexicon are given in figure fig:webprop_lexicon.

I think this approach is extremely promising, but I have not yet had the chance to try it out on sub-Google-sized corpora. However, I do have a small Python implementation for reference:
Once you have a distributional matrix, there are lots of things you can do with it:
The central challenge for using these approaches in sentiment analysis is that they all tend to favor content-level associations over sentiment associations. That is, if you feed them the full vocabulary of your corpus, or the top n words from it, then you are unlikely to get sentiment-like groupings back. Some methods for addressing this challenge: