Sentiment Symposium Tutorial: Language and cognition
- Overview
- A pervasive, challenging phenomenon
- Affect and emotion
- Style and social meaning
- Meaning and use
- Perspective
- Commitment and linguistic structure
- Non-literal language
- Summary of conclusions
This section provides a brief overview of results from linguistics
and cognitive psychology concerning the dimensions of affectivity and
the ways in which attitudinal and emotional information is
expressed.
Communication depends crucially on information about speaker
attitudes and perspectives, and hearer inferences about that
information.
"Sam bought that damn bike."
- Frustration: I've been trying to discourage Sam
from wasting $6,000 on a bike he doesn't need.
- Exuberance: I've been hoping that Sam will
buy the $6,000 road bike so that I can try it.
- Solidarity: You and I have been losing races to
Sam ever since ...
- ...
Our understanding of what is conveyed by damn
in this (or any) case depends on what we know about the speaker, the
hearer, and their relationship, their goals and preferences, and the
information they have already exchanged about the topic in
question. That is, apprehending the sentiment is as deep a problem
as cognitive science has to offer.
As a result, sentiment analysis is hard. We
haven't yet discussed the models and techniques involved in the results
of figure fig:others, but
the picture is intuitively clear: whereas classifying spam messages or picking
out traditional topics is a largely solved problem, sentiment analysis
results typically do not exceed 90% accuracy for realistic
problems. (Where the reported figures are better than this, you might ask
about the underlying class distribution,
over-fitting, and
out-of-domain robustness.)
Part of the challenge is that sentiment information is blended and
multidimensional. We try to approximate it as a classification
problem, but this is often inappropriate. I think no social
networking site brings out this fact more clearly than
the Experience
Project, where users upload stories about themselves that are
often impossible to categorize, since they involve a wealth of
different kinds of sentiment information (and elicit correspondingly
complex reactions from readers).
Table tab:ep
provides a few examples of texts that really ought not to be
classified along any single emotional dimension.
I think computational sentiment analysis is not yet at the
point where it can decide between cognitive theories of emotion
or affect, but existing theories can be very useful when analyzing
data, particularly for:
- Formulating annotation schemes
- Understanding natural and derived labels and clusters
- Reducing the dimensionality of existing labels
- Finding useful sentiment contrasts and alignments
Scherer's
(1984) typology of affective states
(figure fig:affect)
provides a broad framework for understanding sentiment. In
particular, it helps to reveal that emotions are likely to be just one
kind of information that we want our computational systems to identify
and characterize.
Plutchik's
(2002) Wheel of Emotions
(figure fig:wheel)
is a proposal for how to relate emotions to one another. It's also
helpful for the color scheme it provides, which can inform
visualization choices.
Ekman's
(1985) theory of emotions is based in facial expressions
but is intended to have broad applicability;
see figure fig:ekman.
It's often important to distinguish author from reader
perspectives, as these are likely to elicit different emotions. Some
examples are given in table tab:reactions.
Of course, we might see many other combinations as well, but these are
prominent on social networking sites.
What linguists discuss under the rubric of social meaning includes
a lot of Scherer's interpersonal stance and emotional traits.
Speaking in the social world involves a continual analysis and
interpretation of categories, groups, types, and personae and of the
differences in the ways they talk — in social cognition terms,
a development of schemata (Piaget 1954). These emerge as we come to
notice differences, to make distinctions, and to attribute meaning
to them. Thus we construct a social landscape through the
segmentation of the social terrain, and we construct a linguistic
landscape through a segmentation of the linguistic practices in that
terrain.
(Eckert 2008: 455)
Some topics that are of particular relevance to social media:
- Dialects: where does the author come from, and
how does that affect how I apprehend her message?
- Literacy levels: is the author educated, and does
that matter in this context?
- Slang and jargon: is the author at home in this
context? Does she possess specialized knowledge? Is she a true
insider or a pretender?
There is an additional layer of complexity: for some of these
signals, we send them intentionally in order to convey extra
meaning. Others just seep out because they are not under our
control.
A lot of sentiment information is highly context-dependent.
When I think about my own understanding of the words and phrases of my
native language, I find that in some cases I am inclined to say that I
know what they mean, and in other cases it seems more
natural to say that I know how to use them.
(Kaplan 1999)
Keeping track of perspectival information is essential for robust
utterance understanding. This is particularly true for evaluative
language, which is always interpreted from some kind of subjective
position.
The following quotation
from Lasersohn
2005 also points out how complex the relationship between
sentiment and subjectivity/objectivity is, in that even our subjective
claims are meant to have some broad applicability beyond our own
preferences.
Our basic problem is that if John says This is
fun and Mary says This is not fun,
it seems possible for both sentences simultaneously to be true
(relative to their respective speakers), but we also want to claim
that John and Mary are overtly contradicting or disagreeing with
each other [...]
A very complex shifting of perspectives
(from Harris
and Potts 2009):
While shopping at one of my local Apple stores the other day, I
overheard an earnest conversation about safeguarding Mac computers
against things like viruses and trojans. The customer and companion
were new to Mac life and were convinced that they should be very
worried about viruses. The Apple salesperson on the floor repeatedly
assured them that they would not need extra antivirus protection for
their Mac. The customer then argued that Symantec makes an antivirus
program for Macs, therefore, it must truly be a credible threat,
otherwise there would be no such products. Some antivirus products are
even sold in Apple stores. I’ve heard similar arguments before: if
companies like Symantec or McAfee make antivirus applications for the
Mac, then Macs must truly be vulnerable somehow, somewhere. Steve Jobs
and the rest of the Apple cronies must be lying.
From Antivirus
Programs for Mac, Snake Oil or Public Service?
Most robust, fast computational models treat documents as bags of
words. In some areas of sentiment, this is basically appropriate,
because some sentiment words and expressions are not directly
influenced by what is around them:
- That was fun :)
- That was miserable :(
In other cases, where the sentiment words are influenced
by what is around them, a bag of words might nonetheless do the job:
- I stubbed my damn toe
- What's with these friggin QR codes?
However, the normal situation is for sentiment words to be
influenced in complicated ways by the material around them:
- It was wonderful.
- He knows it is wonderful.
- It was not wonderful.
- No one found it to be wonderful.
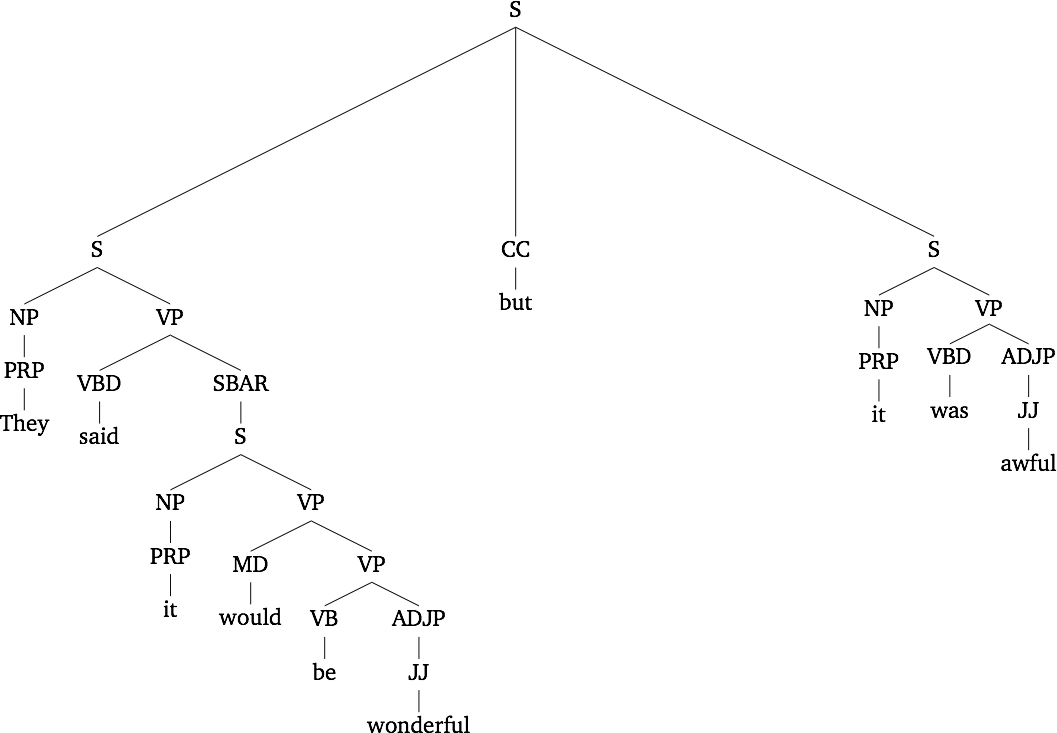
- They said it would be wonderful, but they were wrong: it was awful!
- This "wonderful" movie turned out to be boring.
In linguistic semantics, these influences are analyzed in terms of
semantic scope: in the interpreted structure of these sentences, the
word wonderful is in the semantic scope of
operators that variously negate its scalar meaning or allow the
speaker to back off of the semantic
meaning. Figure fig:scope
begins to suggest how this can be analyzed in terms of the graphical
structure of the underlying sentence.
The effects of non-literal language are extremely challenging. Even
humans are apt to get confused about the intended meaning of some
expressions of this form. We can hope to approximate their effects
with sentiment analysis systems, but they are still likely to be a
leading cause of errors.
- Irony and sarcasm: Oh, this is just great!, as clear as mud
- Implicit comparison: He did a good job for a linguist.
- Hypallage: He's not exactly brilliant.
- Hyperbole: No one goes there anymore.
Properties of sentiment that we should keep in mind when building
systems, conducting experiments, and reporting results:
- Sentiment is blended and multidimensional.
- Author and reader stances often contain very different but related
sentiment information.
- Sentiment is linguistically and socially complex: ideally, we
would know who was talking, to whom, and why, before venturing a guess
about their attitudes and emotions.
- Sentiment is context dependent: the same string might be sincere
in one context and wryly ironic in another.