Figure fig:reviews1
A wealth of user-generated content to guide decision making.

The amount of user-generated content on the Internet has risen exponentially over the last decade, and such content is now always at our fingertips. As a result, nearly all our decision-making is social; before buying products (attending events, trying services, voting for candidates, visiting specialists), we see what our peers are saying about them. The fate of a new offering is often sealed by those evaluations.
Sentiment analysis, the computational study of how opinions, attitudes, emotions, and perspectives are expressed in language, provides a rich set of tools and techniques for extracting this evaluative, subjective information from large datasets and summarizing it. It can thus be vital to service providers, allowing them to quickly assess how new products and features are being received. Recent breakthroughs mean that this analysis can go beyond a general measure of positive vs. negative, isolating a fuller spectrum of emotions and evaluations and controlling for different topics and community norms.
This tutorial covers all aspects of building effective sentiment analysis systems for textual data, with and without sentiment-relevant metadata like star ratings. We proceed from pre-processing techniques to advanced uses cases, assessing common approaches and identifying best practices:
At each stage, I offer concrete advice supported by extensive experimental evidence. There are also interactive demos throughout, and a collection of supporting data sets and implementations.
You're probably here because you have an application for sentiment analysis already in mind. Nonetheless, it's useful briefly survey some standard applications of it in business, finance, and the media.
Customer feedback is now directed not only at companies directly, but also broadcast on the Net via weblogs, Twitter, Facebook, and comments at retailers' websites.
Figure fig:airlines is a sampling of Twitter feedback on airlines. Unusually for the Web (but perhaps not for airlines), the feedback is mostly negative here.

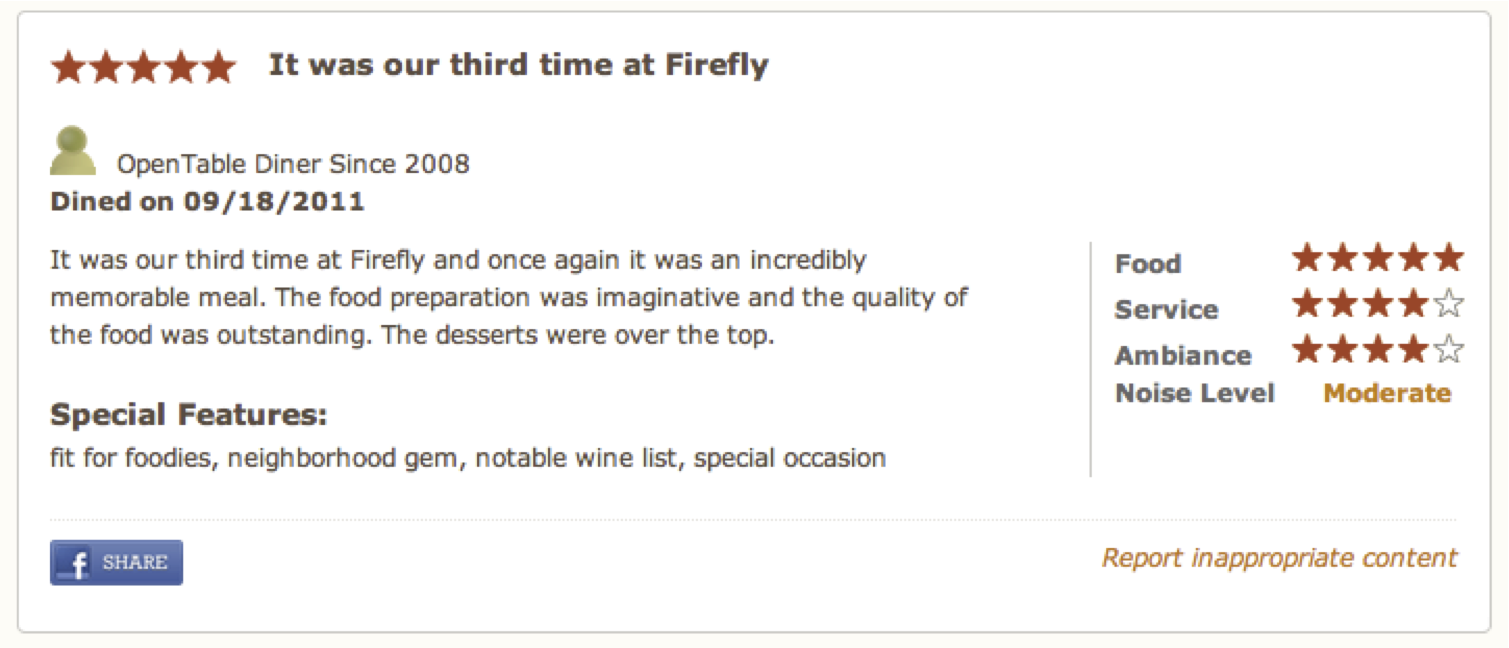
Figure fig:reviews2 suggests how rich the customer feedback can be: targeted evaluations of specific aspects of the product, information about the author/reviewer, and feedback from readers about the review.


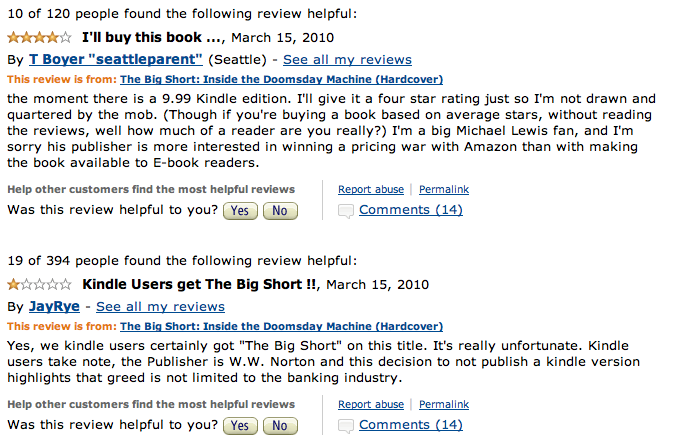
Figure fig:bigshort suggests how challenging it is to process and accurately synthesize all of this data. (See also the wry irony of the Goodreads reviews in figure fig:reviews2.)
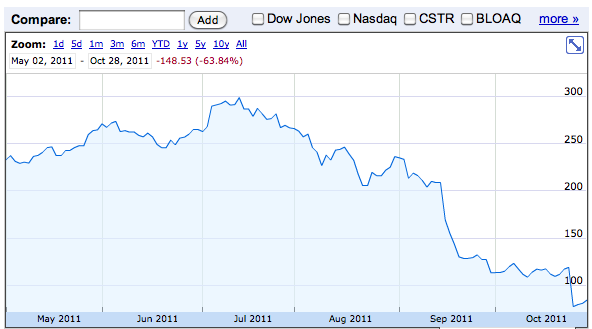
In service industries, a company's stock price is likely to be tied to how its brand is being discussed online (figure fig:netflix). Similarly, public figures find that their own power and influence are intimately tied to the way they are being talked about on social media.
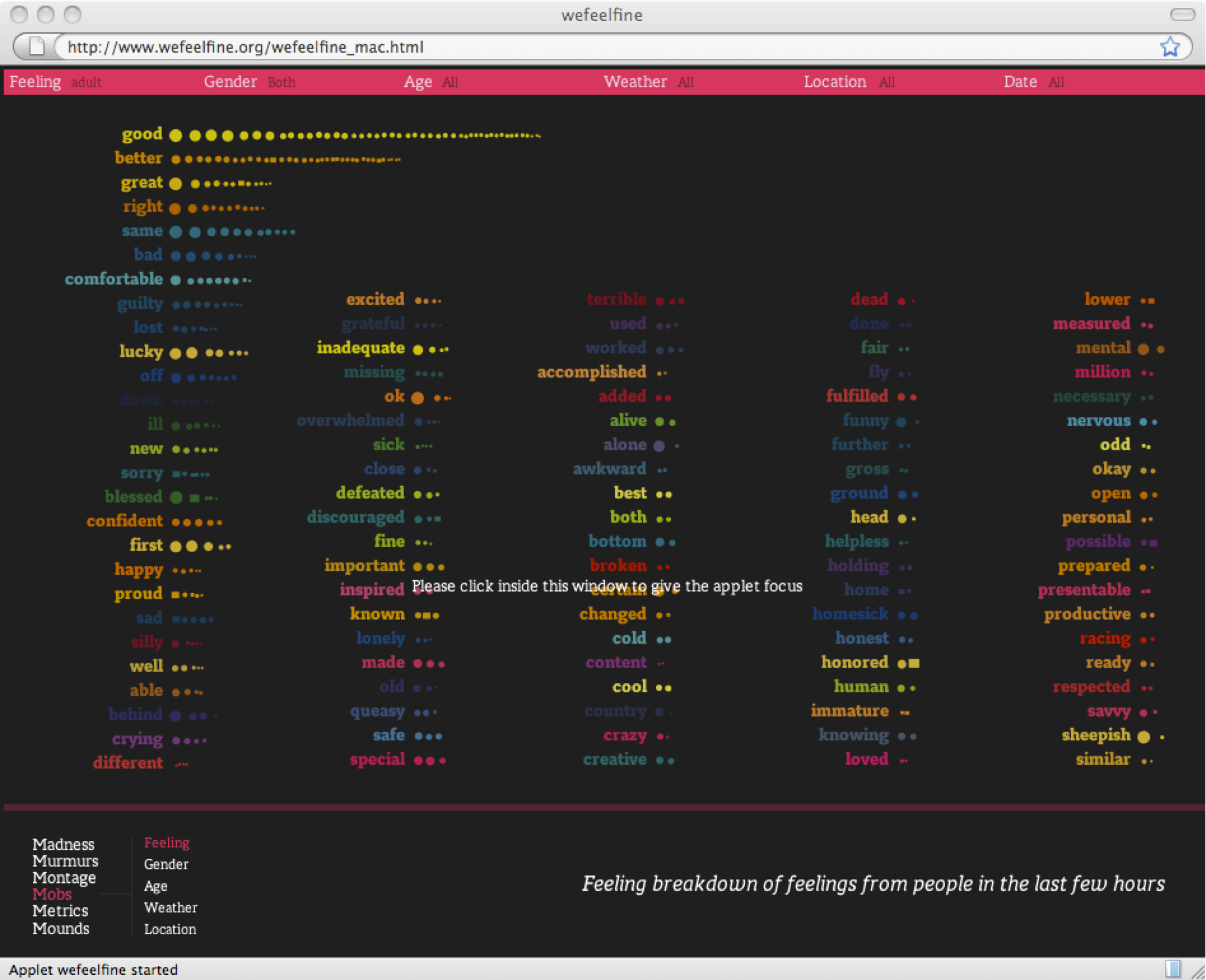
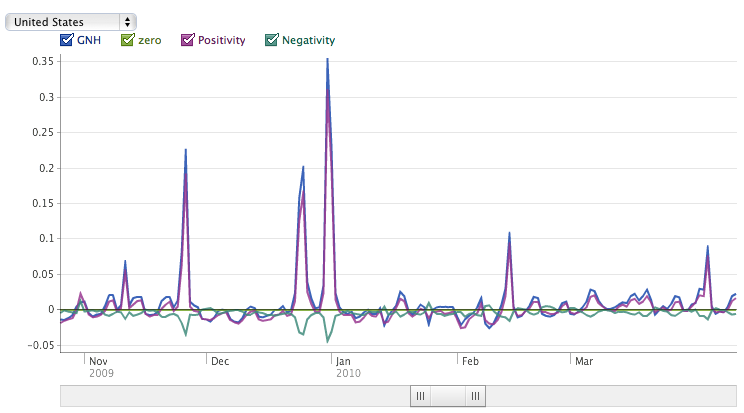
Large-scale projects like We Feel Fine (figure fig:wefeelfine) and Facebook's Gross National Happiness (figure fig:gnh) seek to provide snapshots of the emotional state of the nation. Such information might be used to time a product launch, find receptive markets, and obtain a deeper understanding of a target audience.
Sentiment analysis can complement and inform public opinion polling:
We analyze several surveys on consumer confidence and political opinion over the 2008 to 2009 period, and find they correlate to sentiment word frequencies in contemporaneous Twitter messages.
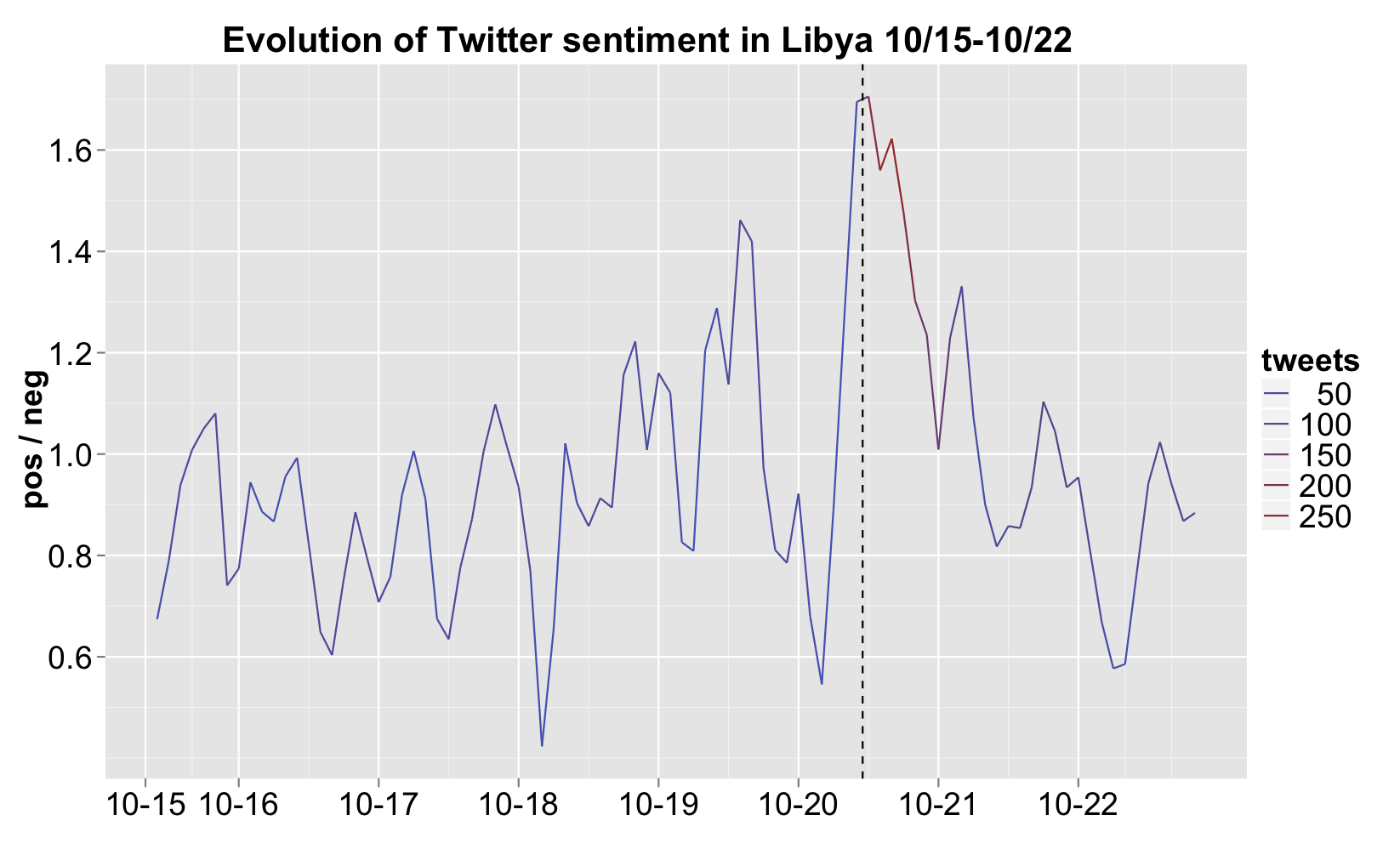
Linguists at UT Austin are using sentiment analysis to get a read on the rapidly evolving situation in the middle east. Apparently, the CIA is playing this game as well.
Sentiment analysis is being used to study media coverage and media bias:
BROOKE GLADSTONE: How do you measure positive and negative press, 'cause you're talkin' about news coverage as much as editorial and opinion.
MARK JURKOWITZ: Yes we are, and this is kind of a new research tool for us. It was a computer algorithm developed by a company called Crimson Hexagon. And we actually used our own human researchers and coders to train the computer basically to look for positive, negative and neutral assertions. Our sample was over 11,000 different media outlets.
The media, the President, and the horse race. On the Media, Oct. 21, 2011.
Text-to-speech technology is increasingly reliable and sophisticated, but it continues to stumble when it comes to predicting where and how the affect will change:
Since the mid-1990s, expanding "digital libraries" have allowed for storage of more phonemes that could be split into even smaller units, adding authenticity to the "voice." But even today's state-of-the-art systems, like AT&T’s Natural Voices, still don't capture the range of human emotion.
The voice in the machine: is lifelike synthetic speech finally within reach?. The Atlantic Monthly, Nov. 2011.
There is evidence that the moods of the nation, as measured by tweets, correlate with changes in stock prices:
Their results showed that rises and falls in the number of instances of words related to a calm mood could be used to predict the same moves in the Dow's closing price between two and six days later.
This is how a Twitter-based hedge fund beat the stock market. The Atlantic Wire, Aug 17, 2011.
It might also help to predict which movies will open big:
we use the chatter from Twitter.com to forecast box-office revenues for movies. We show that a simple model built from the rate at which tweets are created about particular topics can outperform market-based predictors. We further demonstrate how sentiments extracted from Twitter can be further utilized to improve the forecasting power of social media.
For more on such Twitter prognostication, see this xrXiv.org page, this ACL page, and this short New York Times piece by Ben Zimmer.